
- Nftables — a mild autistic ruleset
- Installation
- Emerge
- Configuration
- systemd
- Usage
- Listing tables
- Deleting tables
- chains
- Removing chains
- Deleting rules
- Management
- Backup
- Logging
- Configure syslog-ng
- Troubleshooting
- No such file or directory
- Conflicting intervals
- Restart of nftables or reboot cause blocked connections
- Family netdev and ingress hook
- External Resources
- Ulogd2 in debian
- Configure ulogd2
- Reload ulogd2 configuration
- Nftables configuration
- Full content of /etc/ulogd. conf config file
- Первое правило nftables — никаких правил
- Синтаксис командной строки
- Порядок обработки правил
- Таблицы (tables)
- Цепочки (chains)
- Правила (rules)
- Множества (sets)
- Словари (maps)
- Словари действий (verdict maps)
- Условия отбора пакетов
- ▍ Payload expressions (отбор пакетов на основе содержимого)
- ▍ RAW payload expression (отбор на основе «сырых» данных)
- ▍ Метаусловия (meta expression)
- ▍ Conntrack (connection tracking system)
- Учёт и ограничения
- ▍ Лимиты (limits)
- ▍ Счётчики (counters)
- Разная мелочёвка, примеры
- ▍ Source NAT, Destination NAT
- ▍ Редирект (redirect)
- ▍ Логгирование
- ▍ Балансировка нагрузки (load balancing)
- Nftables. conf
- How to Block IPs from Countries or Continets using NfTables Geoip script
- Clone nftables-geoip GIT repository
- Generate ipv4 and ipv6 mappings
Nftables — a mild autistic ruleset
These rules disable most inter-LAN connectivity. The host wil talk to the gateway, DNS, NTP and DHCP servers. Other nodes might pick up broadcast traffic, but will not be able to communicate with this endpoint.
Installation
Nftables is very modular, so the bare minimum would depend on your intended purposes. A recommended minimum for basic IPv4 firewalling with NAT would be:
KERNEL Nftables kernel requirements
NotePlease note: nftables masquerade will not work if iptables masquerade is in the kernel, so be sure to unload or disable it.
To use family inet for tables with mixed IPv4 and IPv6 rules:
KERNEL Nftables inet family
If this is not enabled only families ip and ip6 can be used.
Early filtering based on network device requires netdev tables support:
KERNEL Nftables netdev family
Emerge
root #emerge —ask net-firewall/nftables
Configuration
- stores the currently loaded ruleset in
- loads the currently loaded ruleset in
- is intended to be called on system shutdown, verifies if SAVE_ON_STOP is enabled in and saves the ruleset
- is intended to be called on system boot and loads the last saved ruleset
- flushes the currently loaded ruleset
- lists the currently loaded ruleset
Don’t forget to add nftables service to startup:
root #rc-update add nftables default
NoteIt is suggested to invoke /etc/init. d/nftables save manually after altering the ruleset. Otherwise, if there is an issue during system shutdown and saving the ruleset fails, the system might boot up with an older ruleset.
systemd
After first setup:
root #touch /var/lib/nftables/rules-save
root #systemctl enable —now nftables-restore
Usage
All nftable commands are done with the nft utility from net-firewall/nftables.
root #nft add table ip filter
Likewise, a table for arp can be created with
root #nft add table arp filter
NoteThe name «filter» used here is completely arbitrary. It could have any name
Listing tables
root #nft list tables ip
The contents of the table filter can be listed with:
root #nft list table ip filter
using -a with the nft command, it shows the handle of each rule. Handles are used for various operations on specific rules:
root #nft -a list table ip filter
Deleting tables
root #nft delete table ip filter
chains
NoteIf You’re running this command from Bash you need to escape the semicolon
A non-base chain can be added by not specifying the chain configurations between the curly braces.
Removing chains
root #nft delete chain ip filter input
NoteChains can only be deleted if there are no rules in them.
root #nft add rule ip filter input tcp dport 80 drop
Deleting rules
To delete a rule, you first need to get the handle number of the rule. This can be done by using the -a flag on nft:
root #nft rule ip filter input tcp dport 80 drop
It is then possible to delete the rule with:
Management
nft supports atomic rule replacement by using nft -f. Thus it is possible to conveniently manage the rules in a text file. Comments may be added to the file by prefixing them with #, as with shell scripts; they can also be appended to the end of rules as comment «», and these will be preserved as-is in nft list output.
Compared to building a ruleset with multiple nft calls in a shell script, this also ensures that failures in such a script do not end with an only partially applied ruleset.
FILE /etc/nftables-localskeleton nftables config file
Backup
You can also backup your rules:
root #nft list ruleset >> backup. nft
NoteIf you are loading your ruleset with nft -f from a file, do not overwrite this file with the nft list ruleset output. This overwrites comments and variable definitions.
Logging
Logging of e. dropped packages is possible by adding a line with the keyword log at the end of the rule-set, e. log prefix «nft. dropinput»;.
Adding a prefix will produce a log entry to /var/log/messages, such as:
FILE /var/log/messagesexample entry in messages file
Jun 07 13:35:19 host kernel: nft. dropinput IN=eno1 OUT= MAC=.
Configure syslog-ng
Logging will be written by default to messages file and will fill up the file with annoying information. Based on using the prefix, the syslog-ng filters will be used to redirect those to its own file nft. log.
FILE /etc/syslog-ng/syslog-ng. confentries for logging nft entries to its own file
Troubleshooting
Before loading new or edited rules check them with nft
No such file or directory
If this error is printed for every chain of a table definition make sure, that the table’s family is available through the kernel. This happens for example if the table uses family inet and the kernel configuration did not enable mixed IPv4 and IPv6 rules (CONFIG_NF_TABLES_INET).
Conflicting intervals
A set definition of IP ranges causes this error if ranges overlap. For example 224. 0/3 and 240. 0/5 overlap completely. Either add auto-merge to the set’s options, drop the range that is fully included or change syntax to 224. 0-255. 255. 255. 255.
CODE Sample Set
Restart of nftables or reboot cause blocked connections
Default configuration of the save and restore function use numeric mode to store the rule set. The persisted rule set could have changed from the original upload from a manually written file. Such a transformation might break things. Therefore make sure:
- that /etc/conf.d/nftables contains the parameter -n for the SAVE_OPTIONS
- and loading your rule set as root yields a working configuration
- and the save and restore cycle of restarting nftables service causes the issue
If all three conditions are met remove the -n parameter from SAVE_OPTIONS in /etc/conf. d/nftables. Then load your rule set again from the manually written file and restart the service again. This cycles through save and restore and should create a fully working rule set.
This affected at least version 0. 9, see bug #819456.
Family netdev and ingress hook
Broken packets should be rejected early which requires an ingress hook for family netdev. This sets up a chain that acts for a dedicated network device before packets enter further processing – improved performance. The configuration looks like this:
CODE Family netdev and ingress chain
Mind the device name enp4s0. If this changes for example when changing hardware or an upgrade changed device naming this family is broken. In turn none of the rules will be loaded. The error looks like this (filename and line numbers differ depending on the host configuration):
CODE Error at chains instead of non-existing device
Check the device name is actually correct and exists, e. ip addr list.
External Resources
- Packet based logging (via libnetfilter_log or ULOG target)
- Flow based logging (via libnetfilter_conntrack)
- SQL database back-end support: SQLite3, MySQL and PostgreSQL
- Text-based output formats: CSV, XML, Netfilter’s LOG, Netfilter’s conntrack
To use libnetfilter_log and libnetfilter_conntrack, a kernel superior to 2. 14 is needed.
Ulogd2 in debian
~ apt-get install ulogd2
The Netfilter logging framework is a generic way of logging used in Netfilter components. This framework is implemented in two different kernel modules:
- xt_LOG: printk based logging, outputting everything to syslog (same module as the one used for iptables LOG target). It can only log packets for IPv4 and IPv6
- nfnetlink_log: netlink based logging requiring to setup ulogd2 to get the events (same module as the one used for iptables NFLOG target). It can log packet for any family.
To use one of the two modules, you need to load them with modprobe. It is possible to have both modules loaded and in this case, you can then setup logging on a per-protocol basis. The active configuration is available for reading in /proc:
~ cat /proc/net/netfilter/nf_log
NONE nfnetlink_log
NONE nfnetlink_log
nfnetlink_log nfnetlink_log
NONE nfnetlink_log
NONE nfnetlink_log
NONE nfnetlink_log
NONE nfnetlink_log
nfnetlink_log nfnetlink_log
NONE nfnetlink_log
NONE nfnetlink_log
nfnetlink_log nfnetlink_log
NONE nfnetlink_log
NONE nfnetlink_log
#define AF_UNSPEC 0
#define AF_UNIX 1 /* Unix domain sockets */
#define AF_INET 2 /* Internet IP Protocol */
#define AF_AX25 3 /* Amateur Radio AX. 25 */
#define AF_IPX 4 /* Novell IPX */
#define AF_APPLETALK 5 /* Appletalk DDP */
#define AF_NETROM 6 /* Amateur radio NetROM */
#define AF_BRIDGE 7 /* Multiprotocol bridge */
#define AF_AAL5 8 /* Reserved for Werner’s ATM */
#define AF_X25 9 /* Reserved for X. 25 project */
#define AF_INET6 10 /* IP version 6 */
#define AF_MAX 12 /* For now
Configure ulogd2
Open file /etc/ulogd. conf and edit:
# this is a stack for logging packet send by system via LOGEMU
stack=log1:NFLOG,base1:BASE,ifi1:IFINDEX,ip2str1:IP2STR,print1:PRINTPKT,emu1:LOGEMU
stack=log2:NFLOG,base1:BASE,ifi1:IFINDEX,ip2str1:IP2STR,print1:PRINTPKT,emu2:LOGEMU
stack=log3:NFLOG,base1:BASE,ifi1:IFINDEX,ip2str1:IP2STR,print1:PRINTPKT,emu3:LOGEMU
Don’t touch first stack and add two another stacks with log2 and log2 NFLOG input plugin and emu2 and emu3 LOGEMU output plugin
Reload ulogd2 configuration
~ /etc/init. d/ulogd2 restart
~ systemctl restart ulogd2
Nftables configuration
Add testing nftables rules like this:
ping to our firewall:
Woalaaaa, It’s Working 🙂
Full content of /etc/ulogd. conf config file
Для облегчения перехода можно конвертировать правила iptables в nftables с помощью утилит iptables-translate, iptables-restore-translate, iptables-nft-restore и т. Утилиты находятся в пакете iptables, который нужно установить дополнительно.
После чего возьмём какую-нибудь команду и пропустим её через iptables-translate. Например, из такой команды:
iptables -A INPUT -i eth0 -p tcp —dport 80 -j DROP
получится вот такая:
nft add rule ip filter INPUT iifname «eth0» tcp dport 80 counter drop
А вот почему она не работает — об этом вы узнаете
в следующей серии
Первое правило nftables — никаких правил
В nftables нет обязательных предопределённых таблиц, как в iptables. Вы сами создаёте нужные вам таблицы. И называете их, как хотите.
Вероятно, самое заметное отличие nftables от iptables — наличие иерархической структуры: правила группируются в цепочки, цепочки группируются в таблицы. Внешне это всё слегка напоминает JSON. И неудивительно, что экспорт в JSON имеется (команда nft -j list ruleset).
Конечно, в iptables тоже есть таблицы и цепочки, но они не выделяются настолько явно. Посмотрите, как выглядит файл конфигурации nftables:
Действующие правила показываются в таком же формате. Чтобы их увидеть, используется команда nft list ruleset. И эта же команда позволяет сохранить правила в файл:
Впоследствии правила можно загрузить:
# nft -f /etc/nftables. conf
Внимание! Загружаемые из файла правила добавляются к уже работающим, а не заменяют их полностью. Чтобы начать «с чистого листа», первой строкой файла вписывают команду полной очистки (flush ruleset).
Можно также хранить правила в разных файлах, собирая их вместе с помощью include. И как вы заметили — можно использовать define.
Синтаксис командной строки
Конечно, вводить многострочные конструкции в командной строке неудобно. Поэтому для управления файерволом используется обычный синтаксис примерно такого вида:
Допустим, нужно заблокировать доступ к ssh и telnet. Для этого используем такую команду:
Как видите, она состоит из простых, понятных частей:
вставить (insert) правило (rule) в семейство таблиц inet, таблицу filter, цепочку input;
запретить (drop) прохождение пакетов, вошедших через интерфейс (iif) eth0, имеющих тип протокола tcp и направляющихся к сервисам ssh или telnet
Примечание: номера портов для сервисов берутся из файла /etc/services
Теперь, чтобы удалить это правило, на него как-то нужно сослаться. Для этого существуют хэндлы (handle), которые можно увидеть, добавив опцию «a» в команду просмотра правил. Кстати, необязательно смотреть все правила (nft -a list ruleset). Можно глянуть только нужную таблицу или цепочку:
# nft -a list chain ip filter input
Соответственно, удаление правила выглядит так:
Учтите: в каждой таблице своя нумерация хэндлов, не зависящая от других таблиц. Если сейчас добавить ещё одну таблицу — у неё будут свои handle 1, handle 2 и т. Благодаря этому, сделанные в какой-либо таблице изменения не влияют на нумерацию в других таблицах.
Порядок обработки правил
Если таблицы и цепочки мы добавляем сами — как файервол поймёт, в каком порядке применять правила? Очень просто: он обрабатывает пакеты с учётом семейства таблиц и хуков цепочек. Вот как на этой картинке:
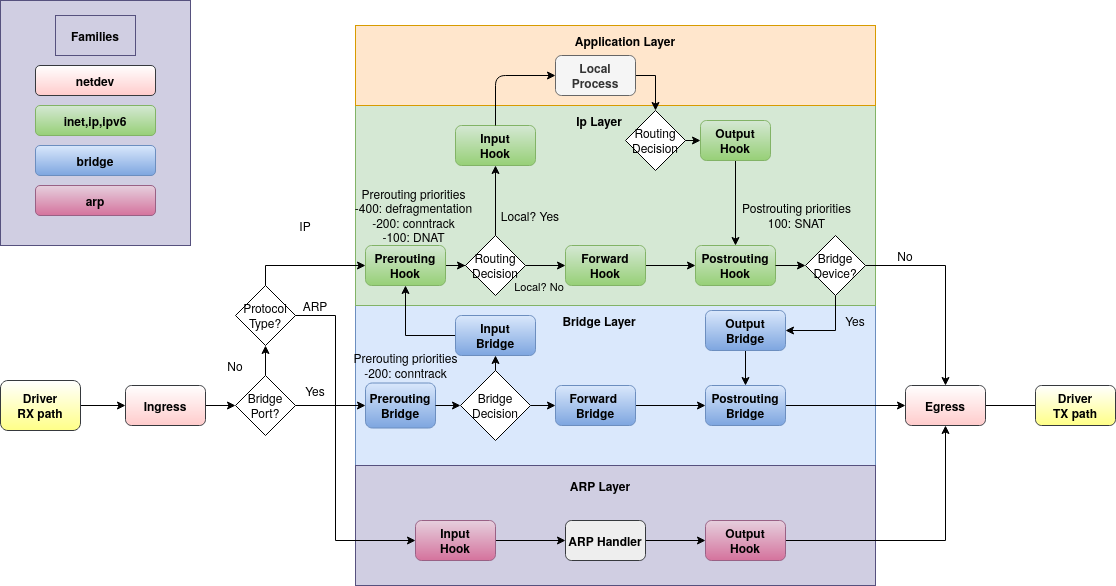
Таблицы могут быть одного из 6-ти семейств (families):
ip — для обработки пакетов IPv4
ip6 — IPv6
inet — обрабатывает сразу и IPv4 и IPv6 (чтобы не дублировать одинаковые правила)
arp — пакеты протокола ARP
bridge — пакеты, проходящие через мост
netdev — для обработки «сырых» данных, поступающих из сетевого интерфейса (или передающихся в него)
Цепочки получают на вход пакеты из хуков (цветные прямоугольники на картинке). Для ip/ip6/inet предусмотрены хуки prerouting, input, forward, output и postrouting.
У цепочки есть приоритет. Чем он ниже (может быть отрицательным), тем раньше обрабатывается цепочка. Обратите внимание на хук prerouting в зелёной части картинки — там это видно.
Чтобы не запоминать числа, для указания приоритета можно использовать зарезервированные слова. Самые используемые – dstnat (приоритет = -100), filter (0), srcnat (100).
Теперь рассмотрим основные части nftables подробнее.
Таблицы (tables)
Поскольку таблиц изначально нет, их нужно создать до того, как создавать цепочки и правила. Именно поэтому не сработало правило после iptables-translate — для него не нашлось таблицы и цепочки.
По умолчанию (если не указана family) считается, что таблица относится к семейству ip. У таблицы может быть единственный флаг — dormant, который позволяет временно отключить таблицу (вместе во всем её содержимым):
# nft add table filter
Примечание: если команда вводится в командной строке — нужно ставить бэкслэш перед точкой с запятой.
Цепочки (chains)
Цепочки бывают базовые (base) и обычные (regular). Базовая цепочка получает пакеты из хука, с которым она связана. А обычная цепочка — это просто контейнер для группировки правил. Чтобы сработали её правила, нужно выполнить на неё явный переход.
Пример в начале статьи содержит обычные цепочки input_wan и input_lan, а также базовые цепочки input, forward и postrouting.
Для базовой цепочки кроме хука и приоритета нужно указать тип:
- filter — стандартный тип, может применяться в любом семействе для любого хука
- nat — используется для NAT. В цепочке обрабатывается только первый пакет соединения, все остальные отправляются «по натоптанной дорожке» через conntrack
- route — применяется в хуке output для маркировки пакетов
Также можно указать policy (действие по умолчанию). , что делать с пакетами, добравшимися до конца цепочки — drop или accept. Если не указано — подразумевается accept.
Пример добавления цепочки:
Переход на обычную цепочку может выполняться одной из двух команд — jump или goto. Отличие состоит в поведении после возврата из обычной цепочки. После jump продолжается обработка пакетов по всей цепочке, после goto сразу срабатывает действие по умолчанию.
Пакет, для которого в handle 3 сработало условие, пойдёт на обработку в цепочку other-chain, а после возврата из неё — продолжит обрабатываться в правиле handle 4.
Если вместо jump будет использовано goto — после возврата из other-chain сработает действие по умолчанию (в этом примере — policy accept).
Из вызванной цепочки можно выйти досрочно с помощью действия return. При этом вызывающая цепочка продолжит выполняться со следующего правила (аналогично jump). Использование return в базовой цепочке вызывает срабатывание действия по умолчанию.
Правила (rules)
Правила можно добавлять и вставлять не только по хэндлу, но и по индексу («вставить перед 5-м правилом»). Правило, на которое ссылается index, должно существовать (то есть, в пустую цепочку вставить по индексу не получится).
Правила можно комментировать:
Заодно здесь показано, как можно использовать интервалы. Для адресов они тоже работают: 192. 168. 15-192. 168. Их также можно применять в множествах, словарях и т. (с флагом interval для именованных).
Множества (sets)
Множества бывают двух типов — анонимные и именованные. Анонимные — пишутся в фигурных скобках прямо в строке с правилом:
Такое множество можно изменить, только изменив правило целиком.
А вот именованные множества можно менять независимо от правил:
Возможные типы элементов у множеств: ipv4_addr, ipv6_addr, ether_addr, inet_proto, inet_service, mark, ifname.
Элементы можно добавлять сразу при объявлении множества:
Также здесь можно увидеть, как указать собственный таймаут для каждого элемента.
Если множество сохранено в файле, для объявления элементов можно использовать define:
Флаги во множествах бывают такие: constant, dynamic, interval, timeout. Можно указывать несколько флагов через запятую.
Если указать timeout — элемент будет находиться во множестве заданное время, после чего автоматически удалится.
Флаг dynamic используется, если элементы формируются на основе информации из проходящих пакетов (packet path).
Можете поэкспериментировать и посмотреть, как оно работает. Для этого удобно использовать ICMP и пинговать целевой компьютер с соседней машины. Допустим, возьмём вот такую комбинацию:
Здесь при приходе первого же пакета icmp в множество ping_set будет добавлен элемент, описанный в фигурных скобках. А когда у элемента сработает условие «rate over 5/minute» (превышена скорость 5 пакетов в минуту) — выполнится описанное в правиле действие (drop). В развёрнутом виде это выглядит так:
На первый взгляд кажется, что пройдёт 5 пингов, и всё остановится. Затем на 30-й секунде элемент удалится, и опять всё пойдёт по новой. Однако, алгоритм ограничения скорости (здесь используется «token bucket») работает по-другому.
Получается вот такое пингование (смотрите на icmp_seq):
PING 192. 168. 201 (192. 168. 201) 56(84) bytes of data. 64 bytes from 192. 168. 201: icmp_seq=1 ttl=64 time=0. 568 ms
64 bytes from 192. 168. 201: icmp_seq=2 ttl=64 time=0. 328 ms
64 bytes from 192. 168. 201: icmp_seq=3 ttl=64 time=0. 367 ms
64 bytes from 192. 168. 201: icmp_seq=4 ttl=64 time=0. 456 ms
64 bytes from 192. 168. 201: icmp_seq=5 ttl=64 time=0. 319 ms
64 bytes from 192. 168. 201: icmp_seq=13 ttl=64 time=0. 369 ms
64 bytes from 192. 168. 201: icmp_seq=25 ttl=64 time=0. 339 ms
На 30-й секунде элемент удаляется, и цикл повторяется — 31,32,33,34,35,43,55.
То есть, первые 5 пингов проскакивают без задержки, затем срабатывает ограничение rate over 5/minute и пакеты начинают отбрасываться. Но через 12 секунд (1 минута / 5 = 12с) первый прошедший пакет удалится из виртуальной «корзины с токенами» и освободит место для прохода следующего пакета. И через 12 секунд — ещё один.
Разумеется, блокировка ICMP мало кому интересна. Обычно это используется для защиты ssh. Прямо в документации есть такой пример:
Здесь сделан интересный «финт ушами», который заключается в том, что сделано два множества с разными таймаутами. Первое детектирует превышение скорости пакетов, а действием у него назначено добавление элемента во второе множество, которое и используется непосредственно для блокировки.
Хотя, на мой взгляд, вместо add для blackhole лучше использовать update. Разница в том, что update при каждом вызове перезапускает таймаут элемента. Таким образом, блокировка будет действовать непрерывно, пока первое множество будет детектировать флуд и обновлять таймауты второго множества. А в примере из документации блокировка каждую минуту ненадолго снимается.
Словари (maps)
Словари похожи на множества, только хранят пары ключ-значение. Бывают анонимными и именованными. Анонимный:
И, разумеется, элементы именованных словарей можно добавлять и удалять.
Словари действий (verdict maps)
Это вариант словарей, где в качестве значения используется действие (verdict). Действие может быть таким: accept, drop, queue, continue, return, jump, goto.
Пример правила c анонимным verdict map:
Пример с именованным:
Обратите внимание: в правиле перед ключевым словом vmap нужно указать, что будет использоваться в качестве ключа (здесь — ip saddr). Этот ключ должен иметь тип значения, совпадающий с указанным в определении словаря (в этом примере — type ipv4_addr). Для ipv4_addr в качестве ключей могут быть ip saddr, ip daddr, arp saddr ip, ct original ip daddr и пр. Все возможные варианты описаны вот здесь.
Условия отбора пакетов
Позволяют использовать несколько условий одновременно (логическое И):
Правило сработает, если ip saddr == 1. 1 И ip daddr == 2. 2 И ip protocol == tcp
Конкатенации можно применять в словарях:
И в verdict maps:
▍ Payload expressions (отбор пакетов на основе содержимого)
Это те условия, которые отбирают пакеты на основе информации, содержащейся в самих пакетах. Например, порт назначения, адрес источника, тип протокола и т.
Условий очень много, поэтому я приведу только их список. Впрочем, во многих случаях их назначение понятно из названия. Если нет — всегда можно посмотреть в документации.
▍ RAW payload expression (отбор на основе «сырых» данных)
Это условие, которое выбирает из пакета указанное количество бит, начиная с заданного смещения. Бывает полезным, если нужно сопоставить данные, для которых ещё нет готового шаблона. у пакетов разных протоколов по заданному смещению находятся разные данные, сначала нужно отобрать подходящие пакеты (в примере ниже — с помощью meta l4proto).
Синтаксис выглядит так:
Например, выберем пакеты протоколов TCP и UDP, идущие на заданные порты:
впрочем, для этих протоколов есть готовые шаблоны, так что писать можно проще:
Поскольку TCP и UDP – протоколы транспортного уровня, в качестве base здесь используется заголовок транспортного уровня (transport header => th).
Для протоколов сетевого уровня (например, IPv4 и IPv6) используются заголовки сетевого уровня (network header => nh).
А Ethernet, PPP и PPPoE – это канальный уровень. Для них применяется ll (т. link layer).
▍ Метаусловия (meta expression)
Метаусловия позволяют фильтровать пакеты на основе метаданных. То есть, на основе таких данных, которые не содержатся в самом пакете, но каким-либо образом с ним связаны — порт, через который вошёл пакет; номер процессора, обрабатывающего пакет; UID исходного сокета и прочее. Метаусловия бывают двух типов. У одних ключевое слово meta обязательно, у других — нет:
▍ Conntrack (connection tracking system)
Система conntrack хранит множество метаданных, по которым можно отбирать пакеты. Соответствующее условие выглядит таким образом:
Вероятно, наиболее используемое условие при работе с conntrack — ct state. Которое может иметь значения new, established, related, invalid, untracked.
Остальные возможности conntrack используются гораздо реже. Даже не буду их описывать. А вот несколько примеров c conntrack лишними не будут.
Разрешить не более 10 соединений с портом tcp/22 (ssh):
Следующее правило разрешает только 20 соединений с каждого адреса. Для каждого адреса IPv4 во множестве my_connlimit будет создан элемент со счётчиком. Когда счётчик достигнет нуля — элемент удалится, поэтому флаг timeout здесь не нужен.
При описании множеств уже был пример, как ограничивать скорость пакетов. Это можно делать и с помощью conntrack:
Пустить пакеты в обход conntrack:
Учёт и ограничения
Считают проходящий трафик и срабатывают, когда достигнуто (over) или не достигнуто (until) указанное значение. Пример анонимной квоты:
В этом примере на UDP порт 5060 можно будет передать только 100 МБ данных
Пример именованных квот:
Именованные квоты (в отличие от анонимных) можно сбрасывать:
# nft reset quota inet quota_demo q_until_sip
Или все квоты файервола:
# nft reset quotas
▍ Лимиты (limits)
Используются для ограничения скорости в пакетах или байтах за единицу времени.
Здесь для ICMP установлен лимит 400 пакетов в минуту, для SMTP (TCP порт 25) — 1 кбайт/с. При этом первые 512 байт на SMTP проскакивают без ограничения скорости (burst). Весь остальной трафик блокируется политикой по умолчанию.
Можно уместить ограничение в одном правиле:
Здесь отбрасываются пакеты, которые не влезают в лимит 10 пакетов в секунду.
Аналогично и с объёмом трафика:
# nft add rule filter input limit rate over 10 mbytes/second drop
Если не использовать over – правила применятся к тем пакетам, которые влезают в ограничение. Например:
# nft add rule filter input limit rate 10 mbytes/second accept
В этом правиле будет принят трафик, влезающий в 10 МБ/с. Всё, что превысит этот лимит – пойдёт на обработку в следующие правила или в политику по умолчанию.
Разумеется, burst здесь тоже возможен:
# nft add rule filter input limit rate 10 mbytes/second burst 9000 kbytes accept
Используя хук ingress в семействе netdev можно ограничить трафик на самом входе в систему. Например, уменьшим поступление широковещательного трафика:
# nft add rule netdev filter ingress pkttype broadcast limit rate
over 10/second drop
▍ Счётчики (counters)
Счётчики учитывают одновременно количество пакетов и байт. Анонимный счётчик:
# nft insert rule inet filter input ip protocol tcp counter
Посмотреть результаты можно с помощью list:
# nft list chain inet filter input
Такие счётчики можно просто добавлять к любому правилу с помощью слова counter:
# nft add rule inet filter input tcp dport 22 counter accept
Посмотреть результаты по всему файерволу, таблице или одному правилу:
Сбросить счётчики – такой же синтаксис, только вместо list – reset.
Разная мелочёвка, примеры
В развёрнутом виде:
▍ Source NAT, Destination NAT
Это правило направит трафик с сети 192. 168. 0/24 на интерфейс eth0. Выходящие с интерфейса пакеты получат исходящий адрес 1
Это правило перенаправит входящий трафик для портов 80 и 443 на хост 192. 168. 120
▍ Редирект (redirect)
Перенаправление входящего трафика на другой порт этого же хоста
Исходящий трафик также можно редиректить:
# nft add rule nat output tcp dport 53 redirect to 10053
▍ Логгирование
Пишет информацию о пакетах в системный лог (/var/log/syslog). Примеры:
# nft add rule inet filter input tcp dport 22 ct state new log flags all prefix «New SSH connection: » accept
# nft add rule inet filter input meta pkttype broadcast log prefix «Broadcast »
# nft add rule inet filter input ether daddr 01:00:0c:cc:cc:cc log level info prefix «Cisco Discovery Protocol «
▍ Балансировка нагрузки (load balancing)
Обычный round-robin (равномерное распределение):
Распределение с разными весами:
Переход на цепочку, со случайным распределением и разными весами:
Nftables. conf
flush ruleset
table inet firewall
chain inbound_ipv4
# However, it also lets probes discover this host is alive. # This sample accepts them within a certain rate limit:
chain inbound_ipv6
# accept neighbour discovery otherwise connectivity breaks
icmpv6 nd-neighbor-solicit, nd-router-advert, nd-neighbor-advert accept
# However, it also lets probes discover this host is alive. # This sample accepts them within a certain rate limit:
chain inbound
# By default, drop all traffic unless it meets a filter
filter hook input priority policy drop
# Allow traffic from established and related packets, drop invalid
ct state vmap established : accept, related : accept, invalid : drop
# Allow loopback traffic. iifname lo accept
# Jump to chain according to layer 3 protocol using a verdict map
meta protocol vmap ip : jump inbound_ipv4, ip6 : jump inbound_ipv6
# for IPv4 and IPv6. tcp dport , , accept
# Uncomment to enable logging of denied inbound traffic
chain forward
# Drop everything (assumes this device is not a router)
filter hook forward priority policy drop
# no need to define output chain, default policy is accept if undefined.
How to Block IPs from Countries or Continets using NfTables Geoip script
- It comes with a new command line utility nft whose syntax is different to iptables.
- It also comes with a compatibility layer that allows you to run iptables commands over the new nftables kernel framework.
- It provides generic set infrastructure that allows you to construct maps and concatenation. You can use this new feature to arrange your ruleset in multidimensional tree which drastically reduces the number of rules that need to be inspected until you find the final action on the packet.
I assume you have at least basic experience with the nftables configuration.
Clone nftables-geoip GIT repository
We need to clone the nftables-geoip git repository.
Create our working directory:
~ mkdir -p /etc/rc-local
~ /etc/rc-local
Install git and wget:
~ apt-get install git wget
Clone nftables-geoip git repository:
Go to our new cloned directory:
~ ls -alFh
drwxr-xr-x root root 4. 0K May 14:18 nftables-geoip/
~ nftables-geoip/
~ ls -alFh
drwxr-xr-x root root 4. 0K May 14:18. git/
-rw-r—r— root root 18K May 14:18 LICENSE
-rw-r—r— root root 21K May 14:18 location. csv
-rwxr-xr-x root root 12K May 14:18 nft_geoip. py*
-rw-r—r— root root 3. 2K May 14:18 README
Generate ipv4 and ipv6 mappings
To generate ipv4 and ipv6 mappings, download geoip data from db-ip. com saving the output in the current folder:
nft_geoip. py python script need requests module. You must install it first:
~ apt-get install python3-requests
Run nft_geoip. py script again:
/nft_geoip. py —file-location location. csv —download
Downloading db-ip. com geoip csv file. Writing country definition files. Writing nftables maps geoip-ipv4,6. nft. Done!
~ ls -alFh
drwxr-xr-x root root 4. 0K May 14:40. /
drwxr-xr-x root 4. 0K May 14:18. /
-rw-r—r— root root 17M May 14:39 dbip. csv
-rw-r—r— root root May 14:39 geoip-def-africa. nft
-rw-r—r— root root 8. 3K May 14:39 geoip-def-all. nft
-rw-r—r— root root May 14:39 geoip-def-americas. nft
-rw-r—r— root root May 14:39 geoip-def-antarctica. nft
-rw-r—r— root root May 14:39 geoip-def-asia. nft
-rw-r—r— root root May 14:39 geoip-def-europe. nft
-rw-r—r— root root May 14:39 geoip-def-oceania. nft
-rw-r—r— root root 9. 5M May 14:40 geoip-ipv4. nft
-rw-r—r— root root 9. 2M May 14:40 geoip-ipv6. nft
drwxr-xr-x root root 4. 0K May 14:18. git/
-rw-r—r— root root 18K May 14:18 LICENSE
-rw-r—r— root root 21K May 14:18 location. csv
-rwxr-xr-x root root 12K May 14:18 nft_geoip. py*
-rw-r—r— root root 3. 2K May 14:18 README