HydraScripts is a collection of 888 NFT which was minted on Jan 31, 2022 at the price of 2 SOL. The current floor price is 3.00 SOL which has increased by 117.39% in the last 24h. The total volume sits at 27515.14 and currently have listed total of 52 NFT.
Project description
Привет, Хабр! Меня зовут Александр Дунаевский, я Data Scientist в Сбере и являюсь участником профессионального сообщества NTA. Сегодня хочу рассказать про управление параметрами в Process mining (процессная аналитика) и нюансах этой задачи.
Для работы используется фреймворк Hydra, который здорово облегчает жизнь. В чём вообще проблема? В задачах процессной аналитики требуется постоянно менять входные параметры и сохранять результаты работы. Но при большом количестве запусков возникает потребность в отдельной системе для управления как передаваемыми параметрами, так и логированием. В статье рассмотрим, как фреймворк Hydra может помочь нам с этим. Кому интересно ― просим под кат!
Quick OmegaConf overview
OmegaCong is a YAML-based hierarchical configuration system, with support for merging configurations from multiple sources (files, CLI argument, environment variables). You just need to know YAML to use Hydra. OmegaConf is used by Hydra in the background to handle everything for you.
The main things you need to know are shown in the config file below
Now in main.py you can access the server address as follows
As you can guess from the above example, if you want some variable to take the same value as another variable you should use the following syntax address:${server.ip}. We will later see some interesting use cases of this.
Hydra Scripts
A collection of different visuals that I have created with Hydra, a JavaScript-based web tool for creating synthesized visuals. You can use it in your browser, download it as a package with the Atom IDE, or connect it to your own webpage with the hydra-synth engine, available via npm.
Getting Started
Running user-created scripts via browser
Copy one of the scripts from this repository to your clipboard.
Open the Hydra Editor in your browser (Chrome).
Click the trash can at the top right of the screen to delete the current visual (after admiring the mesmerizing display).
Paste the script from your clipboard into the editor.
Press the play button in the top right of the screen, or press CTRL+SHIFT+ENTER.
Creating your own visuals
The creator of Hydra, Olivia Jack, has written some instructions for using basic functions.
You can easily modify values and press the run button to execute the code and create your own visuals.
Try adding a single oscillator as a source. PLEASE NOTE: high frequency oscillations or bright flashes can trigger photosensitive epilepsy. There is the potential for lots of colorful flashing when using moving sources. I recommend using a relatively low integer or decimal (-5.0 — 5.0) as the first and second parameters when first experimenting with the oscillator source. Many sources have a sync (speed) parameter which can control how much movement is happening.
// apply a difference color filter (with this new perlin noise source) to the oscillator
Reference the complete list of Hydra functions to see a variety of uses for different sources and effects
Pressing CTRL+SHIFT+H will hide/show the code within the editor
The Horrocubes logo is licensed under Creative Commons 3.0 Attributions license
Cardano NFT Minting Policy Script Factory
Horrocubes NFTs leverage the power of Plutus minting policy scripts to create true NFTs; once these NFTs are minted, it is impossible to create a duplicate. The minting policy of this type of NFT takes and validates as a parameter a specific UXTO and makes sure the UTXO is spent during the minting transaction.
Setting up the environment
We will use Nix to provide both Haskell and Cabal, but if you desire, you could also rely on ghcup to manage these dependencies. However, we won’t cover this. You can refer to the official ghcup site for instructions on that.
Nix is an amazing tool that, among other things, allows us to create isolated environments in which we can embed all dependencies needed for an application. These dependencies can even be system-level dependencies. Thus, we can create an isolated environment to ensure the application will work since all required dependencies are available.
<div data-snippet-clipboard-copy-content="$ sh
$ sh <(curl -L https://nixos.org/nix/install) --daemon
Add IOHK Binary Cache. To improve build speed, it is possible to set up a binary cache maintained by IOHK.
Before Nix works in your existing shells, you need to close them and open them again. Other than that, you should be ready to go.
Once Nix is installed, log out and then log back in, so it is activated properly in your shell.
$ nix-shell ./nix/default.nix
This will take approximately five or ten minutes, then, you should see something similar to this:
these paths will be fetched (445.08 MiB download, 5870.53 MiB unpacked):
/nix/store/04jc7s1006vhg3qj4fszg6bcljlyap1a-conduit-parse-0.2.1.0-doc
/nix/store/052kzx9p5fl52pk436i2jcsqkz3ni0r2-reflection-2.1.6-doc
.
.
.
/nix/store/7jq1vjy58nj8rjwa688l5x7dyzr55d9f-monad-memo-0.5.3... (34 KB left)
This creates an environment with all dependencies listed in the “buildInputs” section, with GHC 8.10.4 and Cabal among those.
When you have recent versions of GHC and Cabal, make sure to use GHC 8.10.2 or later:
[nix-shell:~]$ ghc --version
The Glorious Glasgow Haskell Compilation System, version 8.10.4
[nix-shell:~]$ cabal --version
cabal-install version 3.4.0.0
compiled using version 3.4.0.0 of the Cabal library
Plutus tx: Compiling the script
Compile the project.
To compile the script simply run:
$ cabal update
$ cabal build
Execute the project. You must provide the UTXO, the token name and the output name of the file. Those will be passed as arguments to the Plutus script (it is not used by the script right now, but will be required by transactions using the script).
$ cabal run plutus-horrocubes-tokens 0f4533c49ee25821af3c2597876a1e9a9cc63ad5054dc453c4e4dc91a9cd7211#0 MyHorroCubeTokenName ./out.plutus
Where MyHorroCubeTokenName is your actual asset name (i.e, Horrocube00001) and the UTXO is the actual UTXO used to create your NFT.
Note: You must have a running node to run this step.
Note: These instructions and the code for the minting policy were taken from IOHK repositories:
I just modified offchain code to take the token name as parameter.
В середине декабря в твиттер-аккаунте NSA было объявлено о релизе новой ветки Ghidra с долгожданной поддержкой отладки. Теперь с помощью GDB-заглушки и прочих механизмов можно будет выполнять ее пошагово внутри самой Ghidra. Желая отпраздновать это событие, которое совпало с моим домашним карантином, я подготовил небольшой обзор сборки этой версии, включая пример использования ее отладчика для интересной цели.
В этой статье мы:
научимся собирать последнюю (да и любую) версию Ghidra при помощи Docker Container;
настроим плагины Ghidra Eclipse;
выполним сборку программного загрузчика для Ghidra;
прогоним через отладчик программу, использовав GDB-заглушку;
с помощью той же отладки разберемся, как обрабатываются пароли для игры на Game Boy Advance.
Меня очень вдохновила прекрасная работа, которую в этом направлении проделывают stackmashing и LiveOverflow. Советую заглянуть на их канал. В нашем же случае в качестве подопытной программы выступит игра Spiderman: Mysterio’s Menace. В свое время я играл в нее очень много, к тому же всегда приятно снова взглянуть на свои детские увлечения с позиции опыта. Конечная цель – показать, как правильно загружать этот образ ROM через настраиваемый загрузчик и подключать GDB-заглушку эмулятора при помощи отладчика Ghidra.
К сведению: при начале очередного проекта по реверс-инжинирингу важно правильно определить задачи. Например, если мы говорим, что хотим просто разобрать игру, то здесь допустимо огромное число вариантов. Можно, к примеру, разобрать механику обнаружения столкновений, принцип работы ИИ или способ создания карт уровней. В этой же статье конечной целью мы обозначим изучение механизма паролей.
Проект реализуется под Ubuntu 20.04 со всеми последними обновлениями.
Hydra (ETH-001) is the world’s first NFT-integrated sound system and is paving the way for blockchain integration for physical objects as well as experiential events. This NFT is the on-chain cultural ledger paired to the Hydra system (ETH-001) that debuted at ETH Denver 2022. Nested inside this NFT are moments, memories, art, and music from the events it has supported.
Подробнее о проблеме и работе с фреймворком Hydra
Что такое процессная аналитика? Если коротко, то это технология изучения, мониторинга и оптимизации процессов путём применения специальных алгоритмов к журналам событий.
Анализируя модели бизнес-процессов, можно:
находить основные клиентские пути;
обнаруживать лишние действия, избыточные согласования, отмену ранее совершённых действий, задержки выполнения функций и неэффективных исполнителей.
Для решения подобного рода задач в Сбере разработана собственная библиотека, которая получила название SberPM. В декабре 2020 года её опубликовали, вот ссылочка. К слову, есть и подробная статья о ней на Хабре.
Для лучшего понимания того, как она работает, стоит привести пример ― так нагляднее. Вот, например, как выглядит результат применения самых используемых алгоритмов SimpleMiner и CasualMiner на демонстрационном датасете SberPM:
SimpleMiner визуализирует все найденные рёбра, толщина линии зависит от проходимости ребра. CasualMiner визуализирует только однонаправленные связи. Важная задача, с которой сталкивается программист-исследователь, постоянно работающий с задачами в области процессной аналитики и выполняющий проверку большого числа гипотез, ― передача параметров модели/датасета, логирование запусков и сохранение параметров, при которых получился тот или иной результат.
И если в случае двух-трёх параметров и десятка запусков такую информацию можно сохранять вручную, то при их большем количестве потребуется отдельная система для управления передаваемыми параметрами, конфигурациями и логированием запусков. Вручную такую работу уже не выполнишь.
К счастью, изобретать велосипед не придётся, ведь уже существует Hydra — фреймворк на Python с открытым исходным кодом. Он создавался специально для проектов машинного обучения и позволяет гибко работать с конфигурациями моделей, датасетами и другими входными данными.
Вот основные функции фреймворка (источник ― сайт продукта):
иерархическая конфигурация по нескольким источникам;
конфигурация может быть определена или переопределена из командной строки;
автозаполнение командной строки;
локальный или удалённый запуск приложения;
запуск обучения моделей с разными конфигурациями одной командой.
Установка Hydra довольно простая ― на всякий случай приводим инструкцию из официального источника. По указанной ссылке можно ознакомиться с основными нюансами, в статье о них не будем говорить, чтобы не раздувать объём материала. Единственное, укажем основные особенности, которые стоит узнать в самом начале работы с Hydra:
Hydra меняет текущий рабочий каталог. Например, main.py лежит в src/main.py, но вывод покажет, что текущий рабочий каталог ― src/outputs/2022-02-28/11-32-19;
фреймворк будет вести журнал запуска именно в этом каталоге, там же будут и сохраняться все созданные файлы;
все вызовы функций логирования и переданные параметры, включая конфигурационные файлы, будут сохранены в журнале запуска.
Ну а теперь к делу. Используем фреймворк со SberPM
Теперь, когда вы знаете основные принципы работы фреймворка, можно сосредоточиться на его использовании в решении задач процессной аналитики.
Для примера напишем простую программу, использующую несколько демонстрационных датасетов и моделей.
Забегая наперёд, укажем, что все исходные файлы, код и получившиеся файлы находятся в публичном репозитории.
Датасет
Для демонстрации работы фреймворка мы взяли два датасета (журнала событий):
example.csv ― демонстрационная выборка из библиотеки SberPM;
BPI2016_Complaints.csv ― выборка из соревнования BPI Challenge 2016 Complaints.
Конфигурации для них содержатся в папке conf/dataset/, в файлах example.yaml и complains.yaml
Модель
Работа с моделями осуществляется аналогично датасету. Для демонстрации работы фреймворка мы использовали пять моделей:
SimpleMiner ― рисует все найденные рёбра, толщина линии зависит от проходимости ребра;
CasualMiner ― рисует только однонаправленные связи;
HeuMiner ― рисует только те связи, которые больше определённого порога (threshold) ― чем он больше, тем меньше рёбер;
AlphaMiner ― рисует граф в виде сети Петри с учётом прямых, параллельных и независимых связей между активностями;
AutoInsights ― модуль автоматического поиска инсайтов, позволяющий выявлять узкие места процесса и визуализировать на графе.
Конфигурационный файл каждой модели будет содержать только имя модели (например, name: simple), за исключением HeuMiner, поскольку он содержит дополнительный параметр threshold = 0.8.
Основной код
На примере написанной программы давайте разберём, как Hydra работает с другой библиотекой (в нашем случае SberPM).
Начало главной функции, в которую будут передаваться параметры запуска:
На примере написанной программы давайте разберём, как Hydra работает с другой библиотекой (в нашем случае SberPM).
Начало главной функции, в которую будут передаваться параметры запуска:
# Использование шаблона "декоратор" над главной функцией my_app
# Обязательная часть при использовании sberpm
@hydra.main(config_path='conf', config_name='config')
def my_app(cfg : DictConfig) -> None:
mine() использует майнер из SberPM. Поскольку майнеров используется много, то и участок кода довольно большой:
# функция модели - содержит логику выбора майнера по ключу из конфига и реализует каждый вид майнера def mine(dh): model_name = cfg.model.name def make_image(miner): miner.apply() graph = miner.graph painter = GraphvizPainter() painter.apply(graph) painter.write_graph(model_name + '.' + cfg.out_format, format=cfg.out_format) if model_name == 'simple': from sberpm.miners import SimpleMiner make_image( SimpleMiner(dh) ) elif model_name == 'casual': from sberpm.miners import CausalMiner make_image( CausalMiner(dh) ) elif model_name == 'heu': from sberpm.miners import HeuMiner make_image( HeuMiner(data_holder, threshold=cfg.model.threshold) ) elif model_name == 'alpha': from sberpm.miners import AlphaMiner make_image( AlphaMiner(dh) ) elif model_name == 'insight': from sberpm.miners import SimpleMiner from sberpm.autoinsights import AutoInsights auto_i = AutoInsights(dh, time_unit='day') simple_miner = SimpleMiner(dh) # Transition duration auto_i.apply(miner=simple_miner, mode=cfg.mode) graph = auto_i.get_graph() painter = GraphvizPainter() painter.apply_insights(graph) painter.write_graph(model_name + '.' + cfg.out_format, format=cfg.out_format)
В конце нужно только объединить функции:
# загрузка датасета и использование майнера data_holder = create_dataset() mine(data_holder)
Содержимое используемого программой конфига:
### src/conf/config.yaml
defaults: - _self_ - dataset: example - model: simple
out_format: jpg
mode: time
Запуск
Для запуска с параметрами, установленными в config.yaml: python main.py.
Запуск датасета по умолчанию, модели casual: python main.py model=casual.
Множественный запуск датасета complains, модели insight во всех трёх режимах: python main.py dataset=complains model=insight mode=time,cycles,overall -m.
Запуск всех комбинаций датасетов example, complains и моделей simple, casual, heu, insight: python main.py dataset=complains model=simple,casual,heu,insight -m.
Полезные трюки при работе с Hydra
Как показать конфигурационный файл
Для этого нужно напечатать конфиг без запуска программы. Использование: —cfg [выбор]. Выбор может быть:
job ― пользовательский конфиг;
hydra ― конфиг фреймворка;
all ― оба.
Многократный запуск (в т. комбинации параметров)
Основная идея ― множественный запуск модели с разными параметрами с помощью одной команды. Запуск всех комбинаций датасетов example, complains и моделей simple, casual, heu, insight:
Фреймворк запустит программу со всеми возможными комбинациями dataset и model. Результат сохраняется в каталог multirun (вместо outputs). Структура папки после запуска:
Получилось то же самое, что и при обычном запуске, но у нас появилось 4 подпапки. В документации описаны различные режимы работы этой функции.
Весь исходный код, файлы примеров и получившиеся картинки находятся в репозитории SberPM-parameter-management-with-Hydra.
В сухом остатке
Использование Hydra вместе со SberPM сокращает время исследования журналов событий. Особенно это актуально при большом количестве параметров, поскольку созданная нами система берёт на себя большую часть рутинных задач по передаче и сохранению параметров.
Библиотека Hydra ― настоящая палочка-выручалочка, если вы периодически меняете параметры модели, константы, датасеты и если вам важна воспроизводимость. Также стоит отметить, что библиотека поддерживается и постоянно развивается. Единственный заметный недостаток состоит в том, что всё это работает только из консоли, соответственно, запуск в Jupyter notebook ― это проблема.
И да, если у вас есть альтернативные пути решения описанной в статье задачи, давайте обсудим в комментариях.
С другими публикациями по направлению Process Mining и Data Mining можно познакомиться в аккаунте NTA.
Сборка Ghidra
Начнем с основного. Ветка отладчика еще не была включена в официальный релиз, так что мы его будем собирать сами. К нашему везению, уважаемый dukebarman уже создал для этой задачи docker-контейнер, и нам осталось только изменить скрипт build_ghidra.sh для переключения на ветку отладчика:
Мы также настроим для этой версии Ghidra расширения разработки Eclipse, что пригодится нам позже при сборке загрузчика и написании сценариев анализа. Для этого нужно добавить в скрипт build_ghidra.sh следующее:
gradle prepDev
gradle eclipse -PeclipsePDE
Далее следуйте инструкциям в README:
cd ghidra-builder
sudo docker-tpl/build
cd workdir
sudo ../docker-tpl/run ./build_ghidra.sh
Это займет какое-то время, так что можете отвлечься на кофе, а к возвращению вас уже будет ждать свежесобранная Гидра. Готовая сборка находится в workdir/out:
wrongbaud@wubuntu:~/blog/gba-re-gbd/ghidra-builder/workdir$ ls out/
ghidra_9.3_DEV_20201218_linux64.zip
Распакуйте файл и можете запускать Ghidra через скрипт ./ghidraRun. Я распакую содержимое в каталог ghidra-builder/workdir, так как для сборки этой версии мы будем использовать docker-контейнер. Если вы следуете за процессом, то сейчас ваша рабочая директория должна выглядеть так:
wrongbaud@wubuntu:~/blog/gba-re-gbd/ghidra-builder/workdir$ ls
build_ghidra.sh ghidra ghidra_9.3_DEV out set_exec_flag.sh
Сборка плагинов Eclipse
Закончив с Ghidra, можно переходить к сборке плагинов GhidraDev для Eclipse. Эти проекты находятся в каталоге ghidra-builder/workdir/ghidra/GhidraBuild/EclipsePlugins/GhidraDev.
1. Установите Eclipse
Выберите Java IDE
2. Установите CDT, PyDev, и Plugin Development Environment.
Это можно сделать из маркетплейса Eclipse.
3. Импортируйте проекты GhidraDevFeature и GhidraDevPlugin.
Они находятся в каталоге ghidra-builder/workdir/ghidra/GhidraBuild/EclipsePlugins/GhidraDev/
К сведению: после импорта вы можете заметить некоторые ошибки сборки. Не обращайте внимания, так как вы просто экспортируете плагин.
4. Теперь перейдем к экспорту:
Plug-in Development -> Deployable Features
ghidradev.ghidradev
Выберите местоположение архива для экспорта плагина.
Жмите Finish.
Теперь у нас есть плагин для настраиваемой версии Ghidra, который можно скачать через Help->Install New Software. При этом мы собрали Ghidra из ветки debugger, а также настроили расширения разработки Eclipse, получив возможность создавать плагины для нашей новой версии Ghidra.
К сведению: я хочу подчеркнуть, насколько полезно заглядывать в документацию Ghidra. В ней содержится все необходимое, начиная с мануалов по P-Code и заканчивая инструкциями по сборке и экспорту плагинов.
Создание загрузчика ROM
Для успешного анализа образа ROM нам понадобится определить все области памяти и периферийные устройства GBA. И снова, к нашей удаче, SiD3W4y уже написал для этого решение на GitHub.
Задача загрузчика Ghidra в настройке всех необходимый областей памяти, определении отладочной информации и символов, которые могут присутствовать в файле, а также выдача всей доступной информации о целевом файле. Упомянутый выше загрузчик описывает все основные периферийные устройства GBA и прекрасно подойдет для нашей задачи, так что начнем с его копирования в тот же каталог ghidra-builder/workdir, поскольку для сборки будем использовать тот же контейнер docker, с помощью которого собирали Ghidra.
Здесь мы: 1. Запускаем docker-контейнер. 2. Собираем расширение GhidraGBA, указывая путь к месту установки. 3. Копируем каталог расширений Ghidra, чтобы он показывался под меню Install Extensions. 4. Выходим из контейнера docker.
Запустите Ghidra командой ghidraRun и перейдите в File-> Install Extensions. Выберите загрузчик GhidraGBA и кликните OK. Для применения изменений потребуется перезапустить Ghidra. Теперь при загрузке GBA ROM должно отображаться следующее:
После выполнения автоматического анализа Ghidra неплохо поняла этот образ ROM. В нем определено много функций и выглядит все достаточно хорошо. Следующим шагом будет найти способ сузить нашу область интереса в этом образе. Говоря условно, нам нужно найти иголку в стоге сена. Начнем с выяснения принципа работы системы паролей, для чего просто попробуем ввести несколько их вариантов.
Анализ ROM
При вводе пароля мы наблюдаем такой экран:
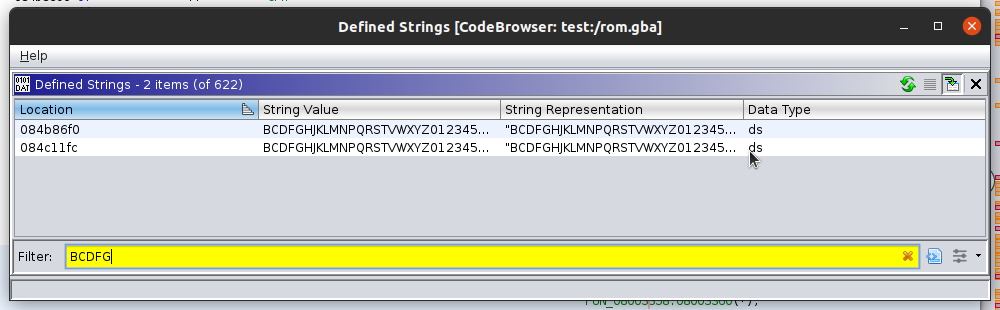
Заметьте, что используются только согласные буквы и цифры от 0 до 9. Сам же пароль состоит из 5 символов. Для реверсинга это будет неплохой отправной точкой. С помощью данной информации можно сузить область интересующих нас функций. Например, давайте просмотрим строки ROM в поиске этих значений. Если открыть окно строк, Window -> Defined Strings, и сделать выборку по пяти первым доступным символам, то мы увидим следующее:
Кое-какой результат имеется – мы обнаружили две точки использования этой строки. Одна расположена в 0x804c11fc, а вторая в 0x84b86f0. При проверке первой строки мы видим, что она передается функции в подпрограмме по адресу 0x8003358:
Обратите внимание на цикл, продолжающий выполнение при переменной < 5. Это говорит о том, что данная функция может оказаться полезной, поскольку пароль как раз содержит именно 5 символов. Давайте отметим ее как passwd_1 и перейдем к остальным местам использования нашей строки символов. Далее она встречается в функции по адресу 0x8002CEC. Вот декомпилированный вариант:
И снова мы видим передачу этой строки в функцию, а также очередной цикл, выполняющий 5 итераций – отметим его как passwd_2 и перейдем далее. Следующая строка встречается по адресу 0x84b86f0 и также используется в двух подпрограммах. Вот первая, расположенная в FUN_0801c37c:
В этой функции мы видим, что FUN_0801b764 вызывается со строкой @ — Accept & — Backspace. Несколько далее та же функция вызывается с переменной, содержащей интересующую нас строку. При дальнейшем рассмотренииFUN_0801b764 мы узнаем, что она копирует данные из второй переменной (строки ASCII) в адрес памяти первого аргумента. Здесь уже нельзя сказать уверенно, но меня кажется, что конкретно эта подпрограмма служит для отрисовки текста на экране, поэтому пока что я ее пропущу и перейду к следующему месту использования строки символов, которое привожу ниже:
Ее задача – копирование строки CRDT5 в указатель ячейки памяти в local_14. Далее мы видим, что в цикле while это значение используется в сравнении:
if (local_14[iVar1] != "BCDFGHJKLMNPQRSTVWXYZ0123456789-"[*(byte *)(param_1 + 0x520 + iVar1)])
Что же происходит здесь? В каждой итерации символ из local_14 сравнивается со значением из нашей строки доступных символов BCDFGHJKLMNPQRSTVWXYZ0123456789-. Такое поведение вполне соответствует предполагаемым действиям функции проверки пароля. Но мы знаем, что iVar1 при каждой итерации увеличивается на 1. Значит ли это, что пароли должны состоять из смежных символов в BCDFGHJKLMNPQRSTVWXYZ0123456789-? Это бы было очень глупо, к тому же строка CRDT5 никогда бы не прошла такую проверку. Если еще раз взглянуть на условие сравнения, то можно заметить, что в нем присутствует переменная param_1, которая тоже используется в качестве индекса, к которому прибавляются iVar1 и 0x520 – затем эти значения используются как INDEX в доступных для набора символах.
О чем это говорит? Переменная param_1 скорее всего указывает на массив смещений, представляющих введенные на экране пароля символы. Например, если мы введем GHDRR, то массив будет содержать [0x4,0x5,0x2,0xd,0xd].
Но давайте не будем забегать вперед и для начала попробуем пароль CRDT5:
Интересно! Мы попали в сцену с титрами!
Выглядит просто, не так ли? Но было бы неплохо выяснить, где именно в памяти хранится наш пароль. Если узнать, куда указывает param_1, то можно вычислить местоположение пароля в RAM и поискать перекрестные ссылки. Ну а раз у нас теперь есть нужная функция, давайте задействуем отладчик!
Отладка ROM
Те, кто повторяет процесс, должны были заметить появление нового инструмента в менеджере проектов:
Обратите внимание на иконку жука – с ее помощью открывается отладчик. Кликнув по ней, вы увидите следующее окно:
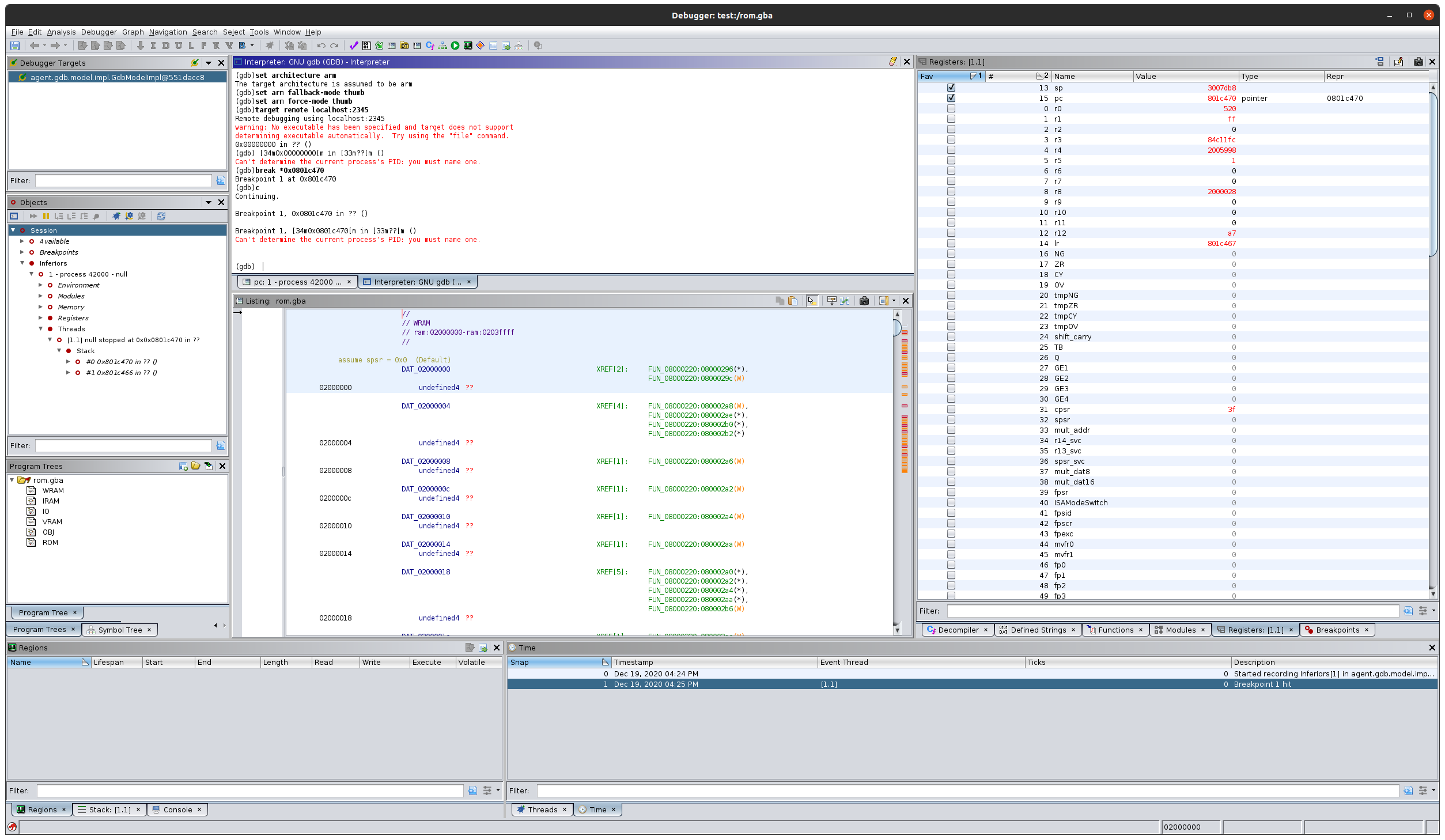
В отличие от обычного представления анализатора здесь находится много дополнительных вкладок и окон. В верхнем левом углу расположено окошко Debugger Targets (цели отладчика), которое мы используем для установки соединения с отладчиком или запуска новой сессии отладки.
Под ним располагается окно “Objects”, показывающее находящиеся в режиме отладки “Objects”. Отсюда можно делать паузу, выполнять шаги и т.д.
В самом низу находится представление трех вкладок: Regions (области памяти), Stack (стек) и Console (консоль).
Справа мы видим окно для показа двух других вкладок: Threads (потоки) и Time (время). Для нашей задачи отладки однопоточной ARM-системы эти окна не пригодятся.
И наконец, оставшаяся справа часть экрана выделена под еще несколько вкладок, которые обычно представлены в разделе анализатора Ghidra. Здесь у нас вкладка Breakpoints, отображающая заданные точки останова:
Вторая вкладка Registers будет обновляться значениями регистра при достижении точек останова:
Последняя же вкладка – это представление Modules, где при необходимости отображаются загруженные модули. Мы же в случае нашего простого приложения ничего в ней не увидим:
Подключение к эмулятору
Для этого проекта я использую эмулятор mGBA, главным образом потому, что он может представлять удаленную GDB-заглушку. Подключаться к нему мы будем с помощью gdb-multiarch. Чтобы выполнить это из представления отладчика нужно в окошке Debugger Targets кликнуть по зеленой вилке (Connect), что вызовет следующее окно:
Здесь есть много опций для удаленной отладки. В целях данной статьи я использую IN-VM GNU gdb local debugger. Я добавил gdb-multiarch в путь команды запуска gdb. После нажатия Connect появится стандартное диалоговое окно:
Теперь нужно запустить сервер. Загрузите образ ROM в mGBA и выберите Tools -> Start GDB Server, всплывет такое окно:
Кликните Start и возвращайтесь в окно отладчика Ghidra. В диалоговом окне gdb выполните следующие команды:
set architecture arm
set arm fallback-mode thumb
set arm force-mode thumb
target remote localhost:2345
break *0x801c470
c
Здесь мы устанавливаем gdb архитектуру, подключаемся к удаленному серверу и в завершении определяем точку останова у функции, которая, как мы считаем, проверяет, нужно ли показывать сцену с титрами. Говоря конкретнее, устанавливаем ее у сегмента, сравнивающего переданный нами символ с извлеченным из строки доступных символов. Рассматривать мы будем этот фрагмент ассемблера:
LAB_0801c470 XREF[1]: 0801c48c(j) 0801c470 69 46 mov r1,sp 0801c472 88 18 add r0,r1,r2 0801c474 a1 18 add r1,r4,r2 ; Обновление указателя на введенный пароль текущим индексом 0801c476 09 78 ldrb r1,[r1,#0x0]; r1 содержит значение индекса переданного символа пароля. Например, "B" == 0, "C"==1, и т.д. 0801c478 c9 18 add r1,r1,r3; r3 содержит указатель на строку доступных символов. Мы добавляем к этому указателю индекс текущего символа пароля. 0801c47a 00 78 ldrb r0=>local_14,[r0,#0x0] ; Загрузка r0 из стека со значением строки "CRDT5" по индексу, указанному r2 0801c47c 09 78 ldrb r1,[r1,#0x0]=>s_BCDFGHJKLMNPQRSTVWXYZ012345678 = "BCDFGHJKLMNPQRSTVWXYZ01234567 ; Загрузка представления символа на основе введенного для пароля значения 0801c47e 88 42 cmp r0,r1 ; Сравнение! 0801c480 00 d0 beq LAB_0801c484 0801c482 00 25 mov r5,#0x0 LAB_0801c484 XREF[1]: 0801c480(j) 0801c484 01 32 add r2,#0x1; Увеличение счетчика индекса 0801c486 04 2a cmp r2,#0x4 0801c488 01 dc bgt LAB_0801c48e 0801c48a 00 2d cmp r5,#0x0 0801c48c f0 d1 bne LAB_0801c470
Введя все вышеприведенные команды, посмотрим, сработает ли точка останова…
Превосходно! Мы не только достигли точки останова, но и зафиксировали все регистры. Теперь проверим, верны ли были все наши предположения в отношении проверки пароля. Прошагаем через несколько инструкций до позиции 0801c474. Здесь мы предполагаем, что r1 будет указывать на массив индексов, представляющих введенные нами символы. Для выяснения этого заглянем в память:
К сведению: если вы делаете отладку удаленно при помощи gdb-multiarch, и при этом некоторые точки останова не срабатывают, попробуйте использовать команду stepi вместо c. Такую проблему я встречал в mGBA ранее, и она не связана с сервером GDB.
Вот оно! Что и следовало ожидать – вместо сохранения фактических символов ascii, вводимых в качестве пароля, сохраняются значения их индексов в таблице доступных символов:
Просто ради проверки, давайте посмотрим, что произойдет, если ввести в качестве пароля CGHDR и установить те же точки останова:
Breakpoint 3, 0x0801c476
Can't determine the current process's PID: you must name one.
(gdb)x/10x $r1
0x2005998: 0x01 0x04 0x05 0x02 0x0d 0x00 0x00 0x00
0x20059a0: 0x00 0x60
Все так и есть! Теперь мы знаем, как сохраняются пароли, и как они выглядят в памяти, а также умеем делать отладку из Ghidra. Думаю, что для данной статьи на этом можно прерваться – в следующей же мы исследуем другие особенности пароля при помощи той же Ghidra и возможностей удаленной отладки GDB.
Learn everything you need to know on how to use Hydra in your machine learning projects. All features of Hydra are discussed with a dummy ML example.
In an effort to increase standardization across the PyTorch ecosystem Facebook AI in a recent blog post told that they would be leveraging Facebook’s open-source Hydra framework to handle configs, and also offer an integration with PyTorch Lightning. This post is about Hydra.
If you are reading this post then I assume you are familiar with what are config files, why are they useful, and how they increase reproducibility. And you also know what a nightmare is argparse. In general, with config files you can pass all the hyperparameters to your model, you can define all the global constants, define dataset splits, and … without touching the core code of your project.
On the Hydra website, the following are listed as the key features of Hydra:
Hierarchical configuration composable from multiple sources
Configuration can be specified or overridden from the command line
Dynamic command line tab completion
Run your application locally or launch it to run remotely
Run multiple jobs with different arguments with a single command
For the rest of the post, I will introduce Hydra features one-by-one with an example of a use case. So follow along, it would be a fun ride.
Understanding Hydra setup process
Install Hydra (I am using version 1.0)
pip install hydra-core --upgrade
For this blog post, I would assume the following directory structure, where all the configs are stored in a config folder, with the main config file being named config.yaml. And for simplicity assume main.py is all the source code of our project.
src├── config│ └── config.yaml└── main.py
Let’s start with a simple example that will show you the main syntax of using Hydra,
Running the script would give the following output
> python main.py The current working directory is src/outputs/2021-03-13/16-22-21The batch size is 10The learning rate is 0.0001
Note: The path is shortened to not include the complete path from root. Also, you can pass either config.yaml or config to config_name.
A lot happened, let’s parse it one by one.
omegaconf is installed by default with hydra. It is only used to provide the type annotation for cfg argument in func.
@hydra.main(config_path="config", config_name="config") This is the main decorator function that is used when any function requires contents from a configuration file.
Current working directory is changed. main.py exists in src/main.py but the output shows the current working directory is src/outputs/2021-03-13/16-22-21. This is the most important point when using Hydra. An explanation follows below.
How hydra handles different runs
Whenever a program is executed using python main.py Hydra will create a new folder in outputs directory with the following naming scheme outputs/YYYY-mm-dd/HH-MM-SS i.e. the date and time at which the file was executed. Think about this for a second. Hydra provides you a way to maintain a log of every run without you having to worry about it.
The directory structure after executing python main.py is (Let’s not worry about the contents of each folder for now)
What happens actually? When you run src/main.py, hydra moves this file to src/outputs/2021-03-13/16-22-21/main.py and then runs it. You can verify this by checking the output of os.getcwd() as shown in the above example. This means if your main.py relied on some external file, say test.txt, then you would have to use ../../../test.txt instead, as you are no longer running the program in src directory. This also means that everything you save to disk would be saved relative to src/outputs/2021-03-13/16-22-21/.
Hydra provides two utility functions to handle this situation
hydra.utils.get_original_cwd(): Get the original current working directory i.e. src.
Let’s recap this using a short example. Suppose we want to read src/test.txt and write the output to output.txt. The corresponding function to do this would be as shown below
We can check the directory structure again, after running python main.py.
The file was written to the folder created by hydra. This is a good way to save intermediate results when you are developing something. You can use this feature to save the accuracy results of your model with different hyperparameters. Now you do not have to spend time on manually saving the configuration file or the command line arguments you used to run the script and creating a new folder for each run to store the outputs.
Note: Each python main.py is run in a new folder. To keep the above output short I removed all the subfolders of previous runs.
The main point is use orig_cwd = hydra.utils.get_original_cwd() to get the original working directory path and then you do not have to worry about hydra running your code in a different folder.
config.yaml — Copy of the config file passed to the function (It doesn’t matter if you pass foo.yaml, this file would still be named config.yaml)
hydra.yaml — Copy of the hydra config file. We will later see how to change some of the defaults used by hydra. (You can specify the message of python main.py --help here)
overrides.yaml — Copy of any argument that you provide through the command line and which changes one of the default value would be stored here
main.log — Output of the logger would be stored here. (For foo.py this file would be named foo.log)
How to use logging
With Hydra, you can easily use the logging package provided by Python in your code without any setup. The output of the log is stored in main.log. A usage example is shown below
import logginglog = logging.getLogger(__name__)
The log of python main.py in this case would be (in main.log)
If you want to include DEBUG also, then override hydra.verbose=true or hydra.verbose=__main__ (i.e. python main.py hydra.verbose=true). The output in main.log in this case would be
Using Hydra for ML projects
Now you know the basic workings of hydra, we can focus on using Hydra to develop a machine learning project. Check the hydra documentation after this post for some of the things not discussed here. And I do not discuss Structured Configs (alternate to YAML files) in this post as you can get everything done without them also.
Recall, the src directory of our project has the following structure
src├── config│ └── config.yaml└── main.py
We have a separate folder to store all our config files ( config) and the source code of our project is main.py. Now let’s get started.
Dataset
Every ML project begins by collecting data and creating a dataset. When working on an image classification project, we use many different datasets like ImageNet, CIFAR10, and more. And each of these datasets will have different hyperparameters associated with them like batch size, the size of input images, the number of classes, the number of layers of the model to use for a particular dataset, and many more.
Instead of using a particular dataset, I use a random dataset as it would make the things general and you can apply the things discussed here on your own datasets. Also, let’s not worry about creating dataloaders, as they are the same thing.
Before discussing the details, let me show you the code and you can easily guess what is happening. The 4 files involved in this example are
To be honest this is pretty much everything you need to use hydra in your projects. Let us see what is actually happening in the above code
In src/main.py, you will see that there are some common variables, namely cfg.dataset and cfg.num_samples that are shared across all the datasets. These are defined in the main config file that we pass to hydra using the command @hydra.main(...).
Next, we need to define some variables specific to every dataset (like the number of classes in ImageNet and CIFAR10). To achieve this in hydra, we use the following syntax
defaults: - dataset: dataset1
Here dataset is the name of the folder that will contain all the corresponding yaml files for each dataset (i.e. dataset1 and dataset2 in our case). So the directory structure would look something like this
And that is it. Now you can define the variables specific to every dataset in each of the above files, independent of each other.
These are called config groups. Every config file is independent of other config files in the folder and we can only choose one of the config files. To define these config groups you need to include a special comment at the beginning of every file # @package _group_.
Note: In Hydra 1.1, _group_ will become the default package and there will be no need to add the special comment.
What is defaults? In our main config file, we need some way to distinguish normal string values from config group values. Like in this case, we want dataset: dataset1 to be interpreted as a config group value rather than a string value. To do this we define all the config groups in defaults. And as you guessed it you provide a default value to it.
Note: defaults takes a list as input, so you need to start every name with a -.
defaults: - dataset: dataset1 # By default use `dataset/dataset1.yamldefaults: - dataset: ??? # Must be specified at command line
We can check the output for the above code.
and
Now pause and think for a second. You can use this same technique to define hyperparameter values for all your optimizers. Just create a new folder called optimizer and write sgd.yaml, adam.yaml files. And in the main config.yaml, you only need to add one more line
defaults: - dataset: dataset1 - optimizer: adam
and you use this to also create config files for learning rate schedulers, models, evaluation metrics, and almost everything else without having to actually hard code any of these values in the main codebase. You no longer need to remember which learning rate you used to run that model, as a backup of the config file used to run the python script is always stored in the folder created by hydra.
Model
There is one special case that you also need to know. What if you want your ResNet model to have different number of layers when using ImageNet vs CIFAR10. The naive solution would be to add if-else conditions in your model definition for every dataset, but that is a bad choice. What if tomorrow you add a new dataset. Now you would have to modify your model if-else condition to handle this new dataset. So instead we define a value num_layers in the config file and then we can use this value to create how every many layers we want.
Suppose we use two models, resnet and vgg. Based on the discussion in the previous topic, we would have a separate config file for each model. The directory structure of the config folder would be
Now suppose we want the resnet model to have 34 layers when using CIFAR10 and 50 layers for every other dataset. In this case the config/model/resnet.yaml file would be
Now we want to set the value num_layers=34 when the user specifies CIFAR10 dataset. To do this we can define a new config group in which we can define all the combinations of the special cases. In the main config/config.yaml we would make the following changes
Here we created a new config group named dataset_model that takes the value specified by dataset and model (like imagenet_resnet, cifar10_resnet). This is some weird syntax as defaults is a list, so you need to specify index before the name i.e. defaults.0.dataset. Now we can define the config file in dataset_model/cifar10_resnet.py
We can test the code as follows, where we simply print out the number of features returned by the config file
> python main.py dataset=imagenetNum features = 50> python main.py dataset=cifar10Num features = 34
We have to specify optional: true, as without it we would need to specify all combinations of dataset and model (if a user enters a value of dataset and model such that we have no config file for that option, then Hydra will throw an error for missing config file).
documentation of this topic.
The rest of the process is the same, create separate config groups for optimizer, learning rate scheduler, callbacks, evaluation metrics, losses, training scripts. In terms of creating config files and using them in your project, this is all you need to know.
Show config file
Prints the config file that is being passed to a function without running the function. Usage --cfg [OPTION] Valid OPTION are
job: Your config file
hydra: Hydra’s config
all : job + hydra
This is useful for quick debugging when you want to check what is being passed to a function. Example,
Multi-run
This is a very useful feature of Hydra. Check the docs for more details. The main idea is you can run your model for different values of learning rate, different values of weight decay using a single command. An example is shown below
Hydra will run your script with all combinations of lr and wd. The output will be stored in a new folder called multirun (instead of outputs). This folder also follows the same syntax of storing the contents in a date and time subfolder. The directory structure after running the above command is shown below
It is the same as outputs except four folders are created here for the run instead of one. You can check the documentation on different ways of specifying the value of the variables to run the script on (these are called sweeps).
Also, this would run your script locally and sequentially. If you want to run your script in parallel across multiple nodes or run it on AWS, you can check the documentation for the following plugins
Joblib — Uses Joblib.Parallel
Ray — Run jobs on AWS cluster or local cluster
RQ
Submitit
Specify help message
You can check the logs of one of your runs (under .hydra/hydra.yaml and then going to help.template) to see the default help message printed by hydra. But you can modify that message in your main config file as follows
hydra: help: template: 'This is the help message'> python main.py --helpThis is the help message
Output directory name
If you want something more specific, than the DATE/TIME naming scheme using by hydra to store the output of all your runs, you can specify the folder name at the command line
That would be it for today. Hope this helps you in using Hydra in your projects.
twitter, linkedin, github
What can I do to prevent this in the future?
If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware.
If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices.
Cloudflare Ray ID: 7345c2fb0e371ece • Your IP:
185.237.165.90 •
Performance & security byCloudflare
Заключение
Сегодня мы познакомились с инструментами, позволяющими собрать Ghidra, рассмотрели некоторые из заявленных возможностей отладчика, с помощью которых смогли произвести удаленную отладку игры на Game Boy Advance. Многое из проделанного вы можете выполнить и без Ghidra, используя только gdb-multiarch, но я хотел познакомиться с этими возможностями и попутно поделиться с вами опытом.
Как всегда, по любым возникшим вопросам обращайтесь ко мне в Twitter. Если же вам интересно побольше узнать о Ghidra или взломе аппаратных средств в общем, можете ознакомиться с подготовленными мной обучающими материалами (англ.).